Machine Learning Model Deployment: From Jupyter to Production
Bridging the gap between ML experimentation and production-ready systems that deliver real business value.
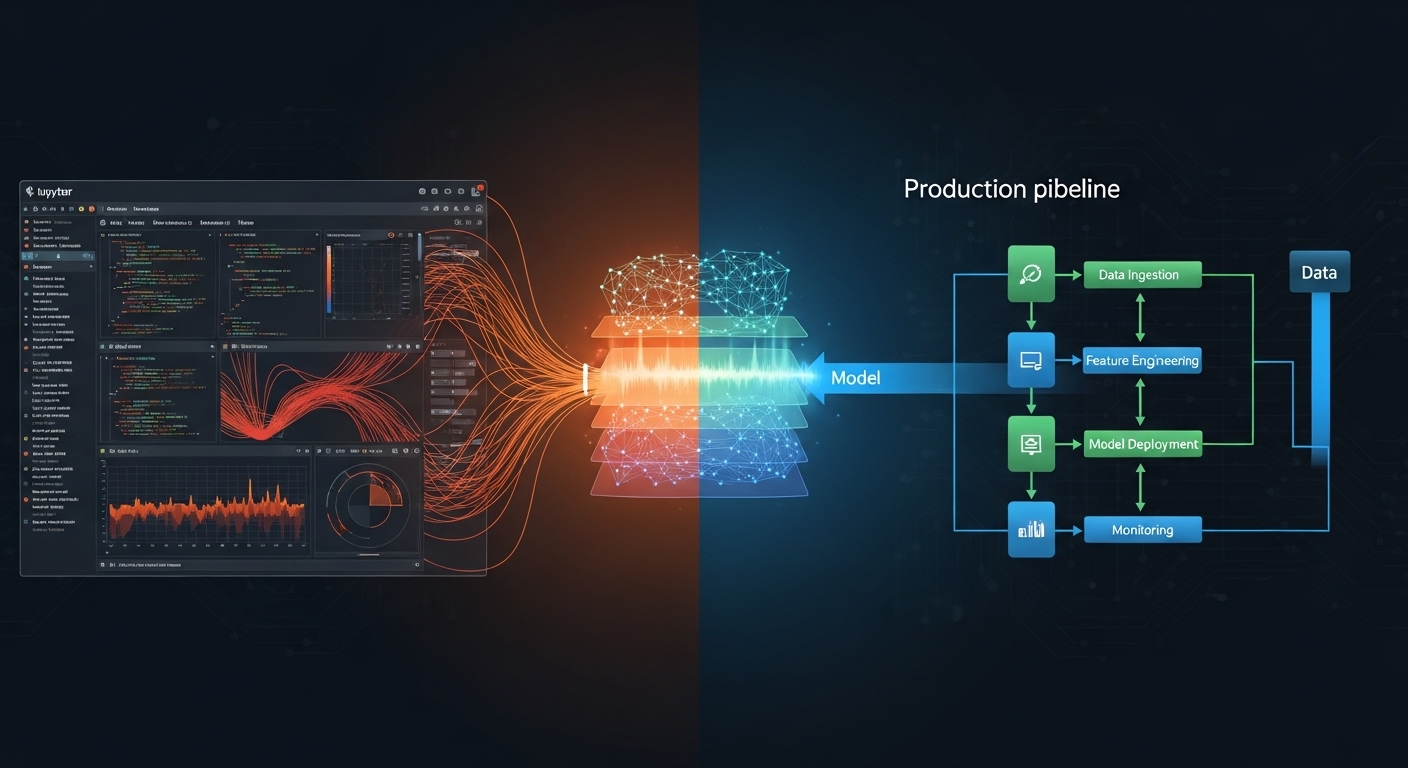
The gap between training machine learning models and deploying them successfully in production environments is often underestimated. While data scientists focus on model accuracy, production systems require reliability, scalability, and maintainability.
The Production ML Lifecycle
Production machine learning involves much more than just training models. A complete ML system includes data pipelines, feature engineering, model training, validation, deployment, monitoring, and continuous improvement.
Data Pipeline Architecture
Reliable ML systems start with reliable data pipelines. Build pipelines that handle missing data, detect drift, and validate data quality at every stage. Use orchestration tools like Airflow or Prefect to manage dependencies and ensure reproducible data processing.
Model Serving Strategies
Batch Prediction
For use cases where real-time predictions aren't required, batch processing offers simplicity and efficiency. Pre-compute predictions on a schedule and store results in a database. This approach works well for recommendation systems, risk scoring, and other scenarios tolerating some latency.
Real-Time Inference
When low latency matters, deploy models as REST APIs or gRPC services. Use model servers like TensorFlow Serving, TorchServe, or general-purpose frameworks like FastAPI with optimized inference code. Implement proper caching, request batching, and load balancing for optimal performance.
Edge Deployment
For privacy-sensitive applications or scenarios with connectivity constraints, deploy lightweight models directly on edge devices. Use model optimization techniques like quantization, pruning, and knowledge distillation to reduce model size while maintaining acceptable accuracy.
Model Versioning and Management
Treat models as artifacts requiring version control and reproducibility. Use MLflow, DVC, or similar tools to track:
- Training data versions
- Hyperparameters and configurations
- Model binaries and metadata
- Evaluation metrics and performance
- Training code and dependencies
This tracking enables reproducing models, rolling back problematic deployments, and understanding performance changes over time.
Feature Engineering in Production
Feature Stores
Centralized feature stores solve the training-serving skew problem by ensuring consistent feature computation across environments. They provide a single source of truth for features, enable feature reuse across models, and support both batch and real-time feature serving.
Online vs. Offline Features
Design feature pipelines that work in both training (batch) and serving (real-time) contexts. Online features must compute quickly with low latency, while offline features can be more complex and computationally intensive.
Model Monitoring
Performance Metrics
Track standard ML metrics like accuracy, precision, recall, and AUC. However, production monitoring requires additional operational metrics: prediction latency, throughput, error rates, and resource utilization.
Data Drift Detection
Monitor input data distributions to detect drift that could degrade model performance. Compare statistical properties of incoming data against training data distributions. Alert when significant drift occurs and retrain models with recent data.
Prediction Drift
Track changes in prediction distributions over time. Sudden shifts might indicate data quality issues, system problems, or genuine changes in underlying patterns requiring model updates.
A/B Testing and Experimentation
Deploy new models alongside existing ones and compare their real-world performance before full rollout. Implement shadow mode deployments where new models make predictions without affecting users, allowing performance comparison with production models in a risk-free manner.
Model Retraining Strategy
Continuous Training
For rapidly evolving domains, implement automated retraining pipelines that trigger based on data volume, time elapsed, or detected performance degradation. Validate new models thoroughly before automatic deployment.
Online Learning
Some applications benefit from models that learn incrementally from new data. Implement safeguards to prevent model degradation from adversarial inputs or data quality issues.
Scalability Considerations
Horizontal Scaling
Design inference services to scale horizontally by adding more instances. Use containerization and orchestration platforms like Kubernetes for automatic scaling based on load.
Model Optimization
Reduce inference latency through model optimization techniques:
- Quantization — Convert floating-point weights to integers
- Pruning — Remove unimportant weights or neurons
- Knowledge Distillation — Train smaller models to mimic larger ones
- Hardware Acceleration — Use GPUs or specialized inference chips
Security and Compliance
Model Access Control
Implement authentication and authorization for model serving endpoints. Rate limit requests to prevent abuse and protect against denial-of-service attacks.
Data Privacy
Ensure training data and predictions comply with privacy regulations. Implement data anonymization, encrypt data in transit and at rest, and maintain audit logs for compliance requirements.
Common Pitfalls and Solutions
Training-Serving Skew
Inconsistencies between training and serving environments cause unexpected behavior. Use the same preprocessing code and feature computation logic in both contexts. Container-based deployment helps ensure environmental consistency.
Model Staleness
Models degrade over time as the world changes. Monitor performance continuously and establish clear retraining criteria before accuracy drops significantly.
Infrastructure Complexity
Start simple and add complexity only when needed. Many organizations over-engineer ML infrastructure before understanding actual requirements. Begin with straightforward deployment approaches and evolve based on real production needs.
Successful ML deployment requires collaboration between data scientists, ML engineers, and platform teams. Focus on building reliable systems that deliver value rather than chasing state-of-the-art model architectures. Production ML is ultimately about impact, not academic perfection.